机器学习笔记
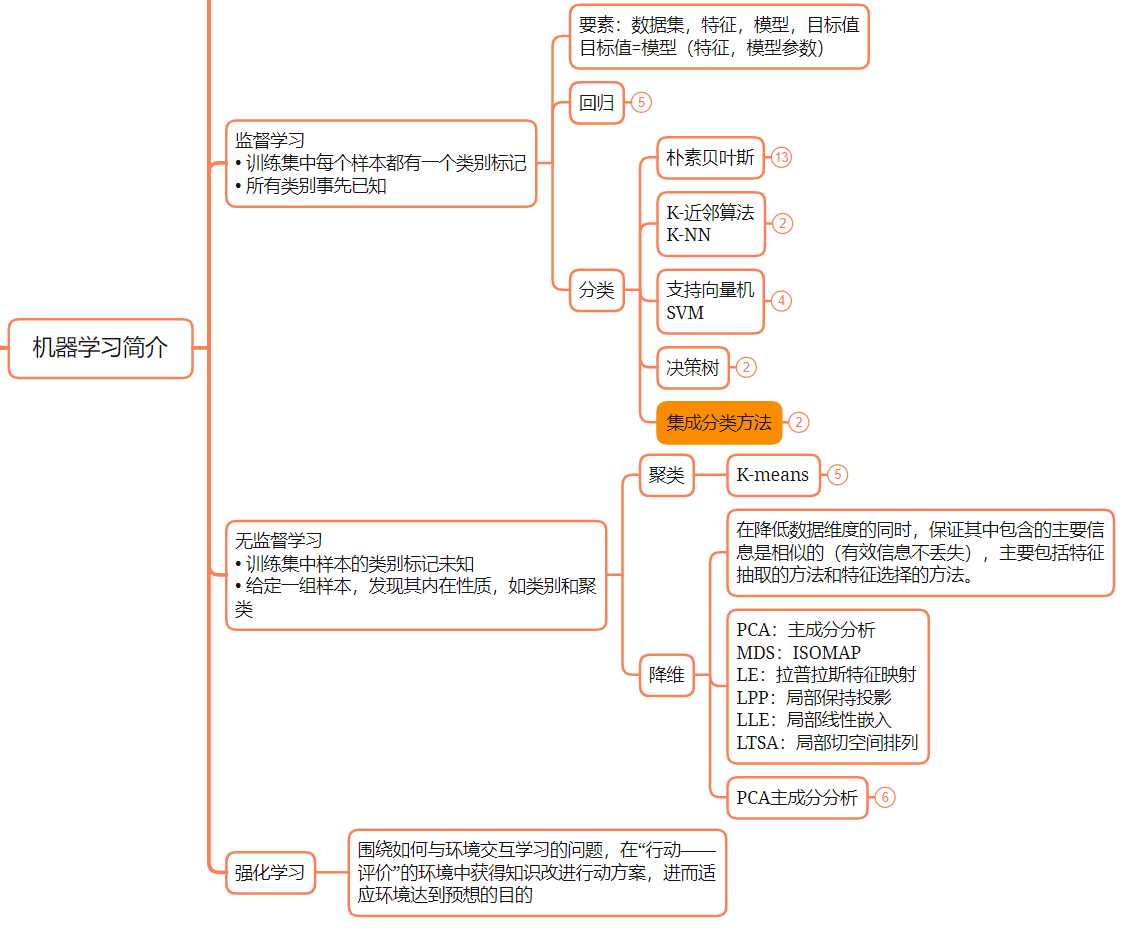
监督学习
• 训练集中每个样本都有一个类别标记 • 所有类别事先已知
回归
用于研究自变量与因变量之间的关系
分类
朴素贝叶斯
先验概率:the initial guess 朴素 naive:忽略了语言的顺序等(难以全),只看出现的概率
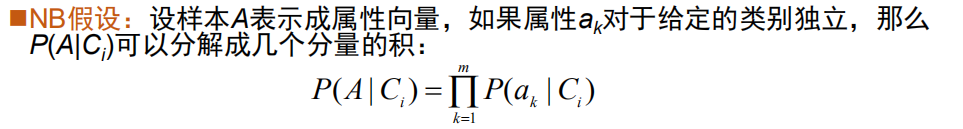
属性拆分为多个,比如大小、颜色。假定特征向量的各分量间相对于决策变量是相对独立的,也就是说各分量独立地作用于决策变量。
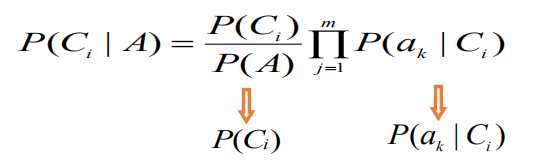

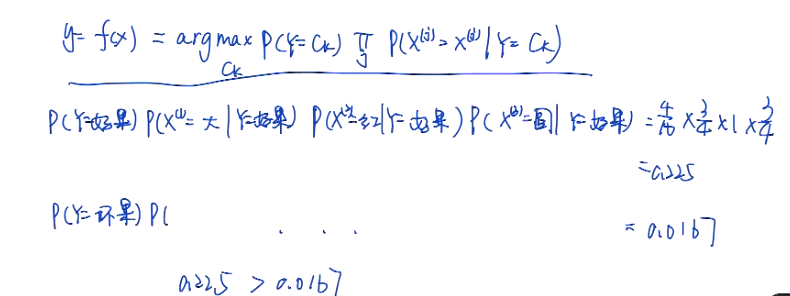
K-NN K-近邻算法
相似度度量


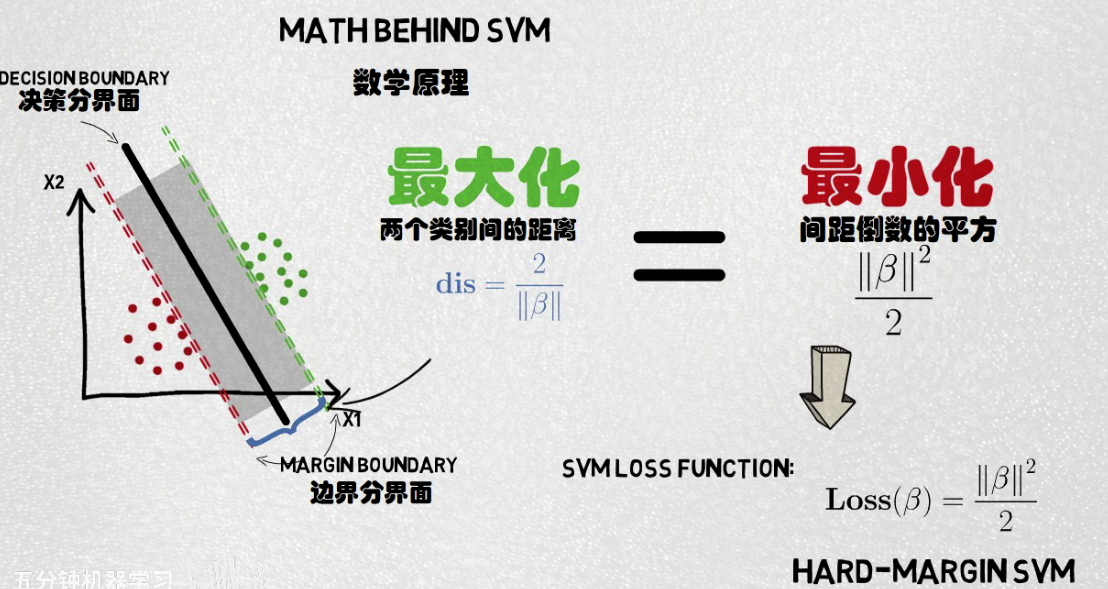
SVM 支持向量机
最优分类面:要求分类面能将两类正确分开(训练错误率为0),且使分类间隔最大
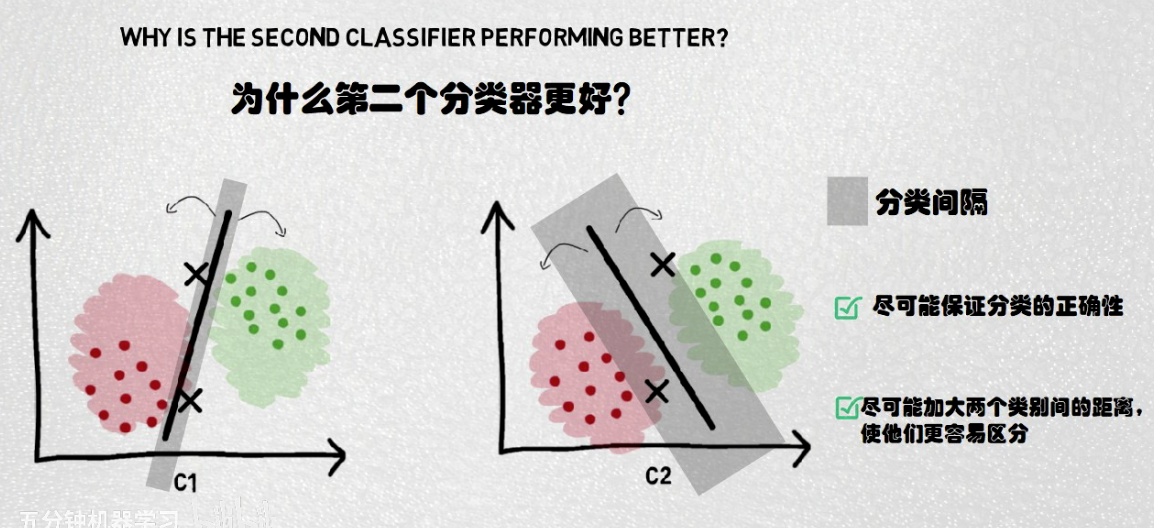
支持向量:
•支持向量是两类集合边界上的点。 •所有非支持向量的数据都可以从训练数据集合中去掉而不影响问题解的结果。
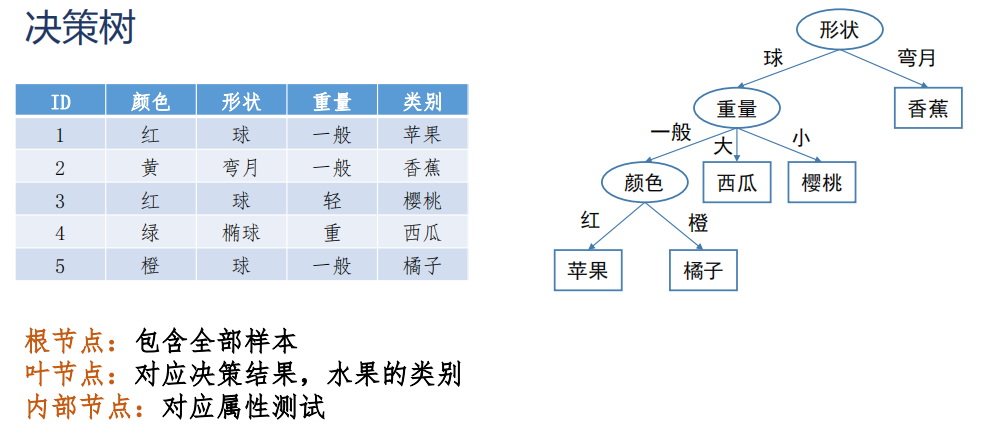
决策树
非叶子节点上是 属性
无监督学习
• 训练集中样本的类别标记未知 • 给定一组样本,发现其内在性质,如类别和聚类
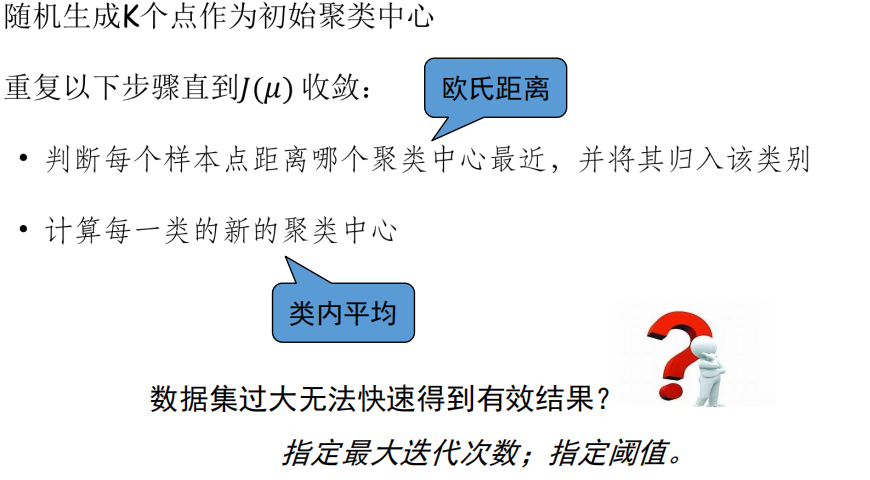
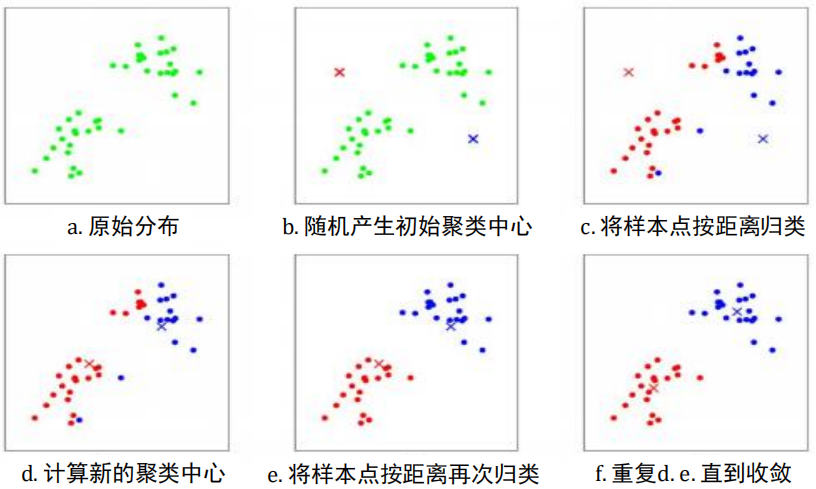
聚类
K-means



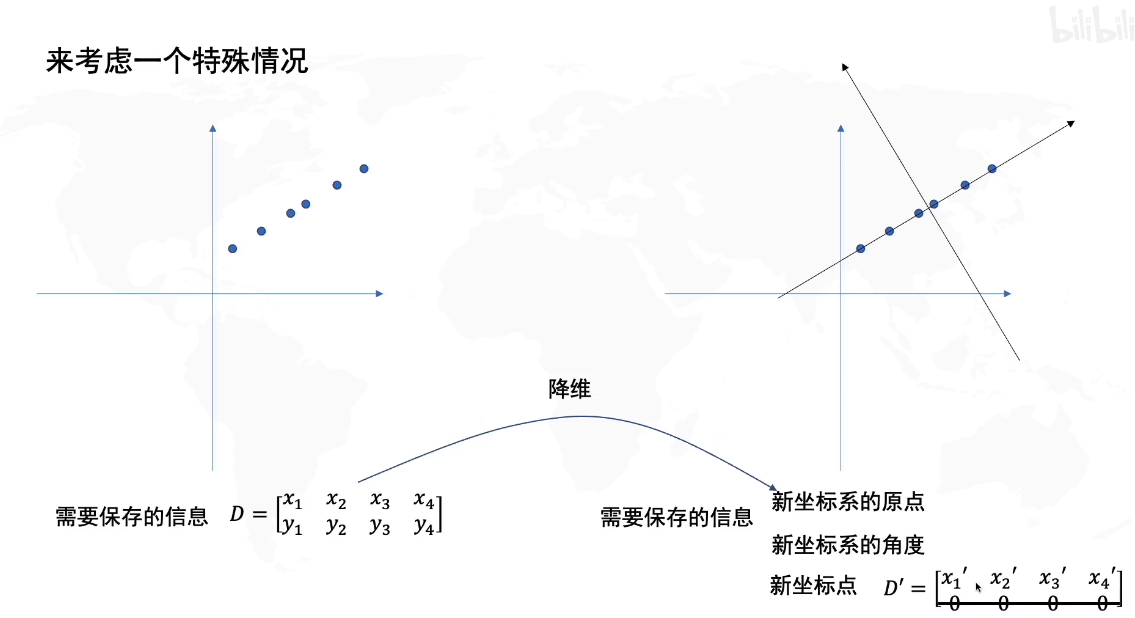
降维
在降低数据维度的同时,保证其中包含的主要信息是相似的(有效信息不丢失),主要包括特征抽取的方法和特征选择的方法。
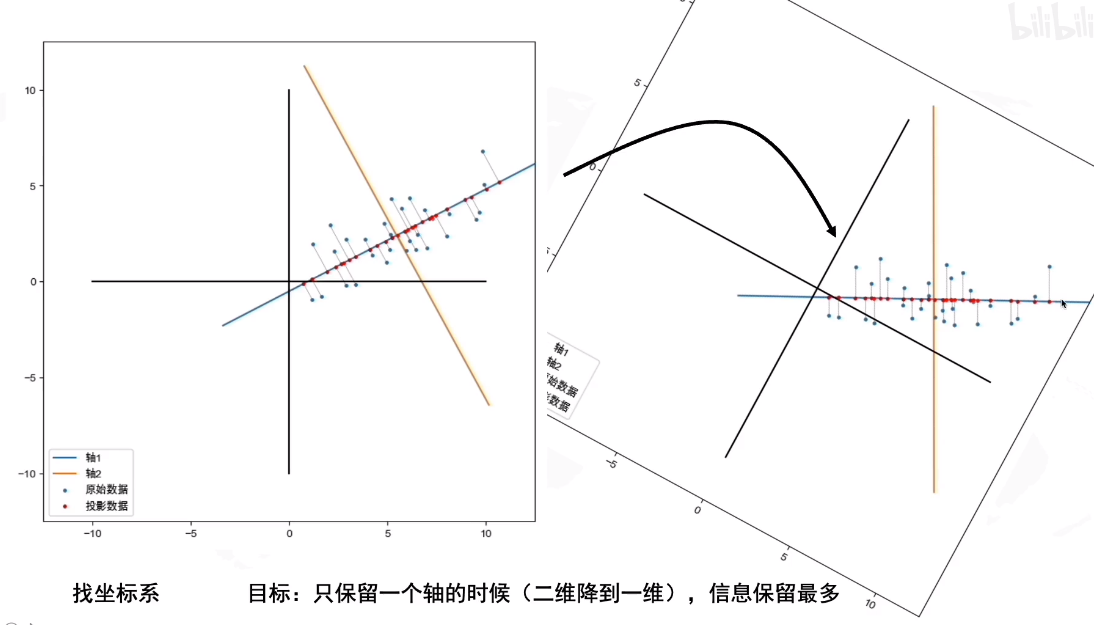
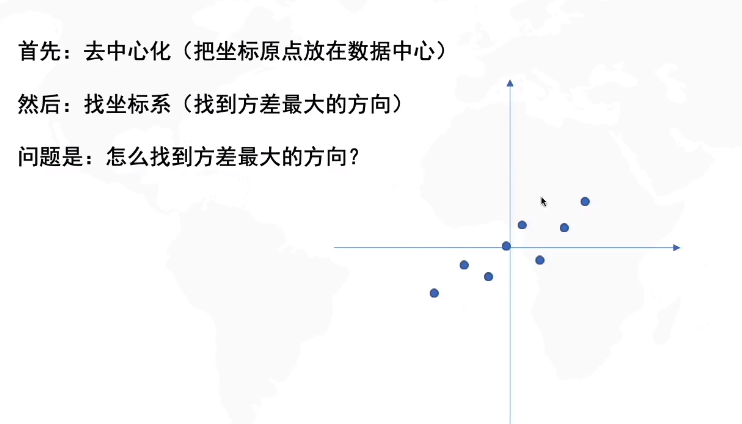
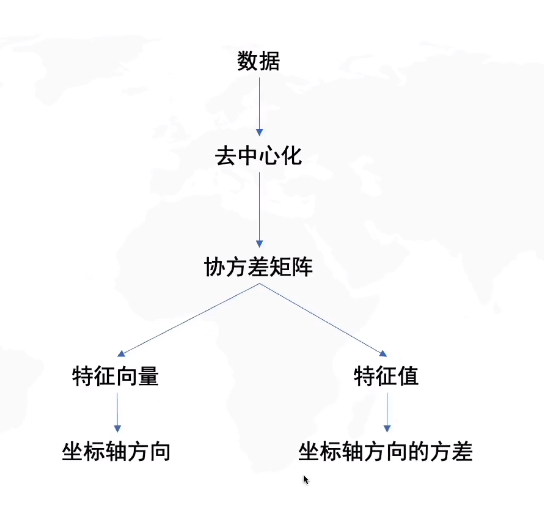
PCA 主成分分析
数据降维后数据尽可能分散 归结为找角度: