Pandas画图基本用法
1.准备工作
最简单的安装方法就是安装Anaconda,其内打包有包括Conda、Python和一堆安装好的工具包,比如:numpy、Pandas、matplolib等。我熟悉的python IDE是Pycharm,所以在安装好Anaconda后,在Pycharm新建一个项目时,将其解释器选为Anaconda中自带的Python程序即可。同时,使用Pycharm开发环境的时候使用Matplotlib要额外在设置中手动从Anaconda中导入该包,原因未知。总而言之,跟其他安装方法比,较为简易。
在使用这些包里面自带的函数之前,要先导入他们的包,常用的两种导入的方式是:
1. from pylab import *
2. import Pandas as pd
3. import numpy as np
4. import Matplotlib.pyplot as plt
前一种为导入pylab中所有的函数,后面则是导入一个包。
2. Matplotlib简易上手
下面几个概念至关重要,在我没搞清之前,死活画不出图,怎么debug,程序都不显示绘图界面……很基本的几个概念是:figure、subplot、axes/axis,figure是绘图界面最底层的载体,可以在它上面放置图纸——subplot和axes,在做所有操作之前都要提前建立好figure和subplot/axes。Figure建立的基本语法形式是:fig = plt.figure()
建立好画板之后,建立图纸,subplot可以理解为figure的子图,axes则可以理解为figure里的图的坐标轴的集合,axes里面有很多具体的轴axis。建立Subplot的时候可以将画板figure划分成几块,基本的语法形式是:
1. ax1 = fig.add_subplot(3, 2, 1)
2. ax2 = fig.add_subplot(3, 2, 2)
3. ax3 = fig.add_subplot(3, 2, 3)
4. ax4 = fig.add_subplot(3, 2, 4)
5. ax5 = fig.add_subplot(3, 2, 5)
6. ax6 = fig.add_subplot(3, 2, 6)
括号里的三个参数必不可少,前两个表示将figure划分为3x2共6块,后面1-6也对应着划分的6个subplot,画出来如下图所示: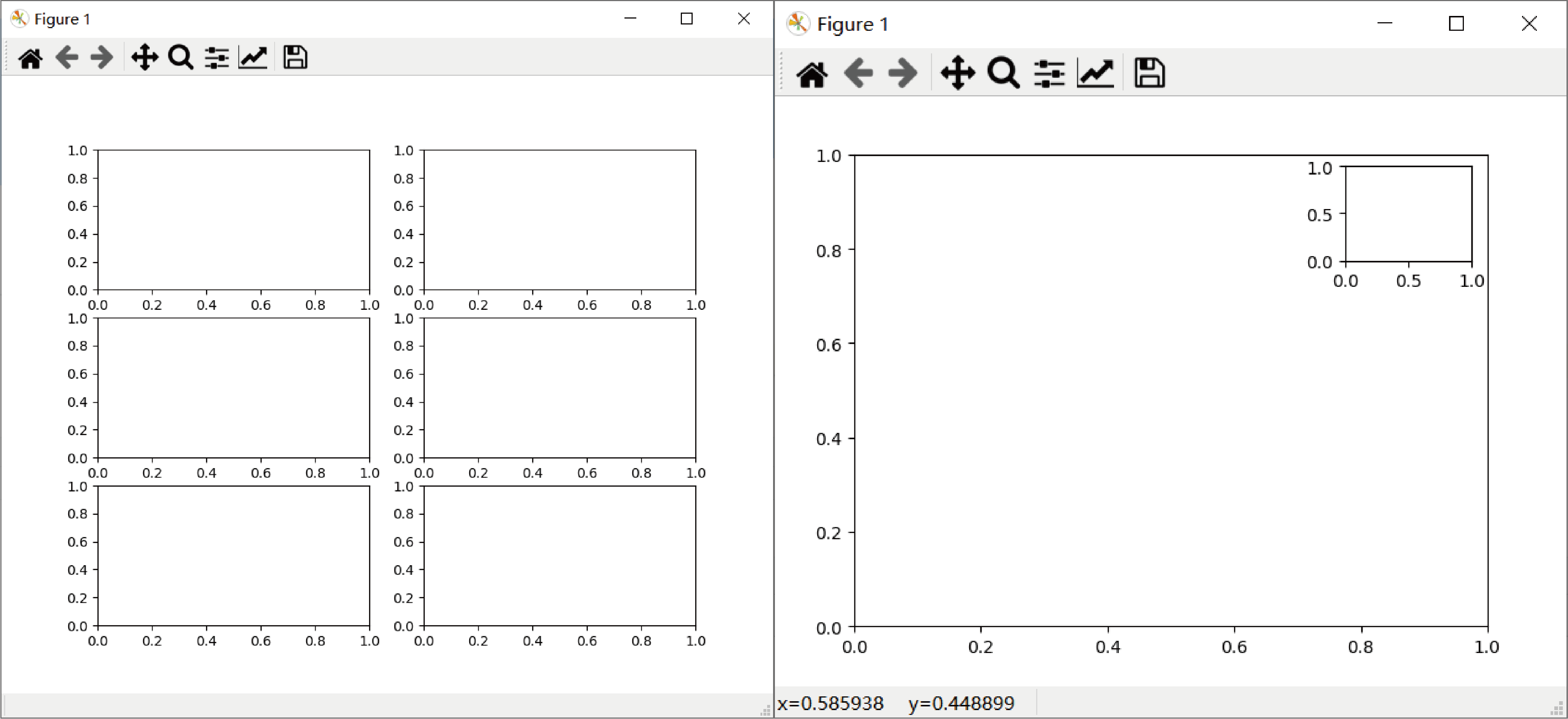
建立axes的时候,相当于建立了一堆坐标轴,比subplot更加自由灵活,可以随意摆布表的位置,比如使用add_axes函数,可以来增加子图:
1. ax1=fig.add_axes([0.1,0.1,0.8,0.8])
2. ax2=fig.add_axes([0.72,0.72,0.16,0.16])
add_axesd的四个参数分别指代左、下、宽、高,均为figure的百分比,上面第一句的具体画法就是从figure画板10%的位置开始绘制, 整个figure窗口就是figure的大小,若从0开始,则坐标轴会贴着弹出的figure窗口的边沿,宽高都是figure的80%,第二句则为从figure的72%的位置开始绘制,宽高都是figure的16%,可以看出画出来最终的效果就是连个叠加的坐标框,图的摆放要比subplot灵活得多。
3.Pandas简易上手
Pandas里内置了几种图表格式,现在挑几个简单的图表类型简单介绍一下:
3.1 基础plot
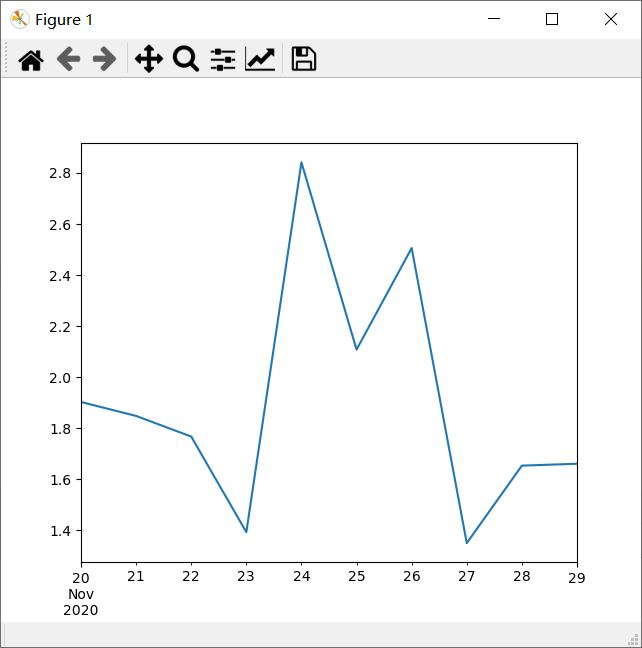
可以通过plot函数直接绘制图形,下面以类似官方文档的方法产生数据来绘制一个图,代码如下:
1. Chen1 = pd.Series(np.random.randn(10),
2. index=pd.date_range('11/20/2020', periods=10))
3. Chen1.plot()
4. plt.show()
其中Series为Pandas中的一个基本数据类型,为带标签的一维同构数组,np则为前面导入的numpy包,我们使用了其中的random函数,np.random.randn(10) 的具体含义就是随机生成10个数,这10个数呈正态分布,我在这里为了看得清楚,选取一个很小的数字10,当数字很大时,可以明显看出其分布情况。横坐标我们使用的是日期,我们这里从2020年11月20日算零点,往后算10天。
后面直接使用plot函数就能绘制出结果,如下图:
使用plot函数还可以很方便地画出多条折线叠在一起加上图例的折线图,囿于图片数量限制,此处不贴出结果,但是可以贴出代码:
1. Chen2= pd.DataFrame(np.random.randn(10, 4),
2. index=pd.date_range('11/20/2020', periods=10), columns=list('ABCD'))
3. plt.figure();
4. Chen2.plot();
5. plt.show()
DataFrame是Pandas中另一个非常重要的数据类型,为带标签的大小可变的二维异构表格,可以看到初始化和前面的类似,此处使用了更多的参数,np.random.randn(10, 4) 比上面的更加复杂,表示生成四组数据,每组里面又有10个数据,则可以对应着画出四条曲线。Colums则是自定义列标签为ABCD,对应着四组数据。
3.2 其他类型plot
Plot函数除了默认的折线图,还有其他很多形式,可以定义kind的类型来使用这些图,kind的种类有bar/barh、hist、box、kde/density、area、scatter、hexbin、pie等。使用kind类型的一种方法如下所示:
1. Chen3= pd.DataFrame([1,2,3,4,5,4,3,2,1])
2. Chen3.plot(kind='bar');
3. plt.show()
该段代码简单地定义了一个DataFrame,按照上面提供的方法,可以画出该DataFrame的一系列图如下:
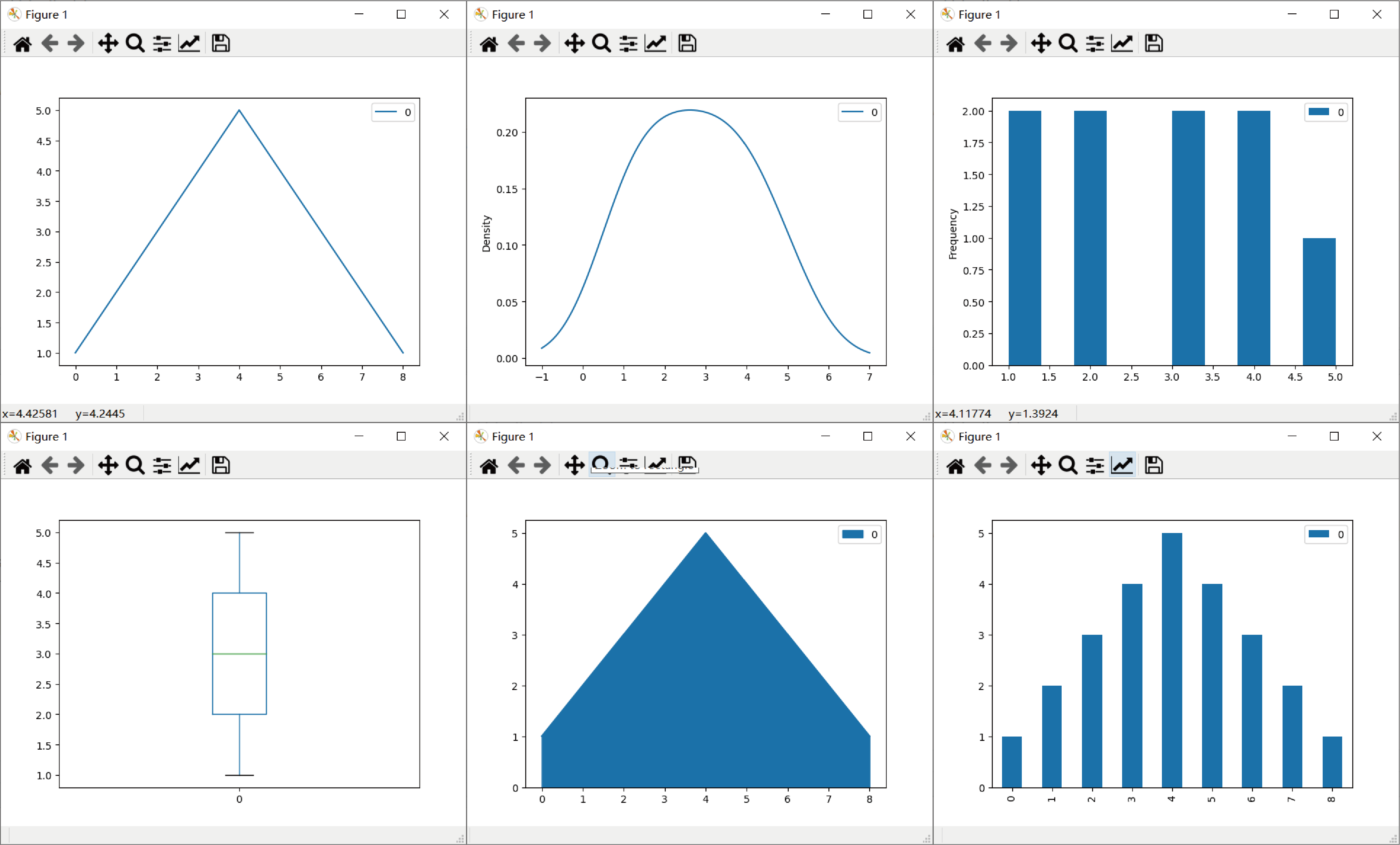
图1.1为普通plot折线图,没有定义kind;图1.2的kind定义为density/kde,是将这9个点连成一条平滑的曲线;图1.3的kind定义为hist,它统计了各个元素出现的累计次数;图1.
4的kind定义为box,从图中可以看出数据的分布情况,可以看到最大为5,最小为1;图1.5的kind定义为area,是以纵坐标为0为基线,将普通的plot的函数与横纵坐标包围的面积标识出来了;图6的kind定义为bar/barh,是普通的柱状图。
以上几种是单一的一元数组可以表示的形式,我们还可以利用以下代码,来演示剩下的几种plot形式:
1. Chen4=pd.DataFrame({'A': [1,2,3,4,5,4,3,2,1],
2. 'B': [60,70,80,90,100,110,120,130,140]},)
3. Chen4.plot.scatter(x='A',y='B')
4. plt.show()
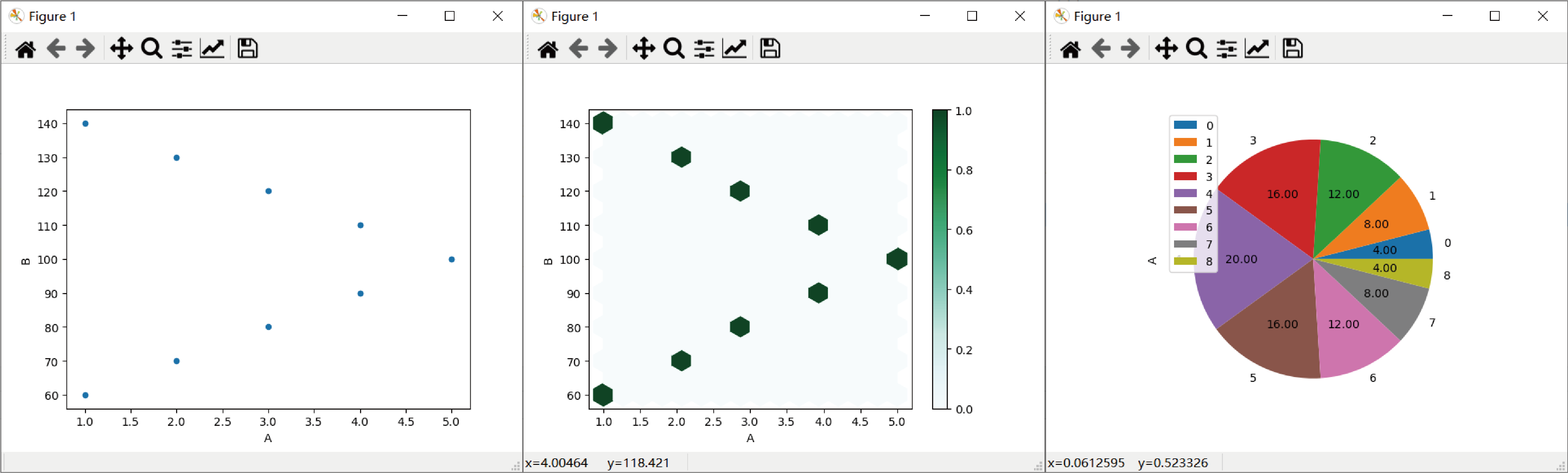
kind为scatter时,为散点图,需要定义横纵坐标名,于是构建字典来初始化DataFrame,并且这里使用了另一种定义plot类型的语法,若使用之前的使用kind来定义的方式,则可以写为Chen4.plot(kind=’scatter’,x=’A’,y=’B’); 两者效果完全一样。
类似地,kind为hexbin时,Chen4.plot(kind=’hexbin’,x=’A’,y=’B’,gridsize=15);可以自定义gridsize,该值越大则表现的六边形越多,六边形越小,我们将girdsize取一个合适值就可以看出数据的分布,多用于分布很密集的数据,在我这个例子里面,优点没有很好地发挥出来。
类似地,Kind为pie时, Chen4.plot(kind=’pie’,y=’A’,autopct=’%.2f’); 为饼状图,指定的y值为每块的数值的名称,在我的例子里是每块的值分别是60,70,80,90,100,110,120,130,140,他们的占比分别为1/25,2/25,3/25,4/25,5/25,4/25,3/25,2/25,1/25,即分别为4/100,8/100,12/100,16/100,20/100,16/100,12/100,8/100,4/100,注意不要弄反。在这里额外定义了参数autopct,是定义图上各色块占比的数字形式,这里是截取二位小数。